
Par Harrison Jones, ASA
La disponibilité croissante des mégadonnées et le recours à l’analyse prédictive sont en train de changer le mode de fonctionnement des assureurs et des actuaires. Dans bien des cas, la question de savoir comment exploiter cette matière première complexe est devenue un défi organisationnel important.
Dans un contexte où les entreprises font face à des pressions concurrentielles croissantes, l’exploitation judicieuse des données et la reconnaissance de leur importance constituent un avantage de premier ordre.
Obtenir de l’information par l’intermédiaire des médias sociaux
Les plateformes de médias sociaux telles que Twitter, Facebook et Instagram sont utilisées partout dans le monde à plusieurs fins. Ce phénomène a pour effet secondaire de fournir d’importantes quantités de données à analyser.
Pour illustrer la façon d’utiliser ces données, nous avons étudié l’exemple du fil Twitter anglais de l’ICA pour montrer la mesure dans laquelle l’analytique du texte la plus basique peut fournir des renseignements utiles. On a extrait tous les tweets de @CIA_Actuaries au moyen du paquetage rtweet R, puis les avons analysés au moyen des paquetages dplyr, ggplot2 et quanteda.
Avertissement : cet article n’aborde pas l’utilisation éthique des données, mais cet élément devrait assurément être pris en considération par les entreprises qui choisissent d’exploiter des sources de données publiques ou privées, y compris des données provenant de Twitter.
Fréquence de publication
Le 24 février 2012, @CIA_Actuaries a publié son tout premier tweet qui se lisait « @ICA_Actuaires Welcome to Twitter! », souhaitant ainsi la bienvenue à son équivalent français. Depuis ce temps, soit au 1er mars 2021, @ICA_Actuaries a publié 2 801 autres tweets. La figure 1 montre le nombre de tweets publiés selon l’année et le mois.
Figure 1 : Nombre de tweets de @CIA_Actuaries selon l’année et le mois
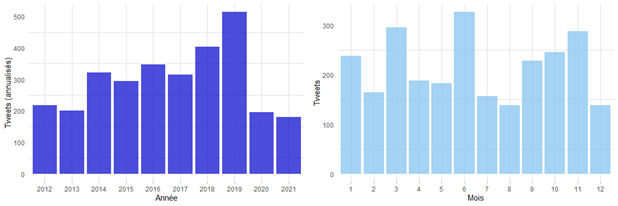
Le nombre de tweets par année affiche une courbe croissante et atteint un sommet en 2019, puis une chute marquée en 2020. La COVID-19 pourrait avoir joué un rôle dans la diminution de la fréquence de publication en 2020, s’ajoutant aux changements apportés à la stratégie de l’Institut relative aux médias sociaux. Dans le premier mois de 2021, @CIA_Actuaries a publié 30 tweets (soit un nombre annualisé de 180), ce qui indique que la tendance vers une fréquence plus faible devrait se poursuivre.
L’examen de mois en mois révèle une baisse de l’activité au mois de décembre et pendant les mois d’été, ce qui est logique puisque ceux-ci coïncident avec les vacances et les Fêtes. On observe également une augmentation considérable de la fréquence de publication en juin, ce qui s’explique du fait que le congrès annuel de l’ICA se tient habituellement en juin.
Partages de tweets
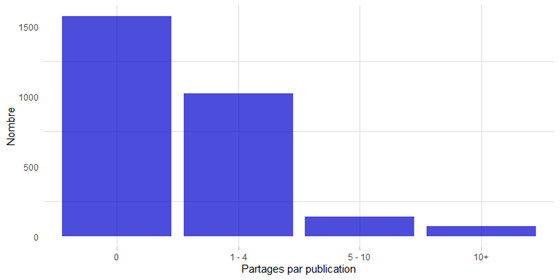
De toutes les publications de @CIA_Actuaries, 1 230 ont fait l’objet de partages (moins de la moitié des publications). Par ailleurs, les publications partagées l’ont été en moyenne 24 fois, ce qui est particulièrement élevé. Deux tweets font augmenter la moyenne : tous les deux publiés lors de la journée Bell cause pour la cause, dans le cadre de laquelle les dons sont fondés sur le nombre de publications et de partages. Outre ces deux valeurs hors normes, il serait intéressant pour l’équipe de l’ICA de déterminer quels sont les tweets qui sont partagés et pourquoi.
Figure 2 : Nombre de partages par publication de @CIA_Actuaries
Fréquence des mots-clics
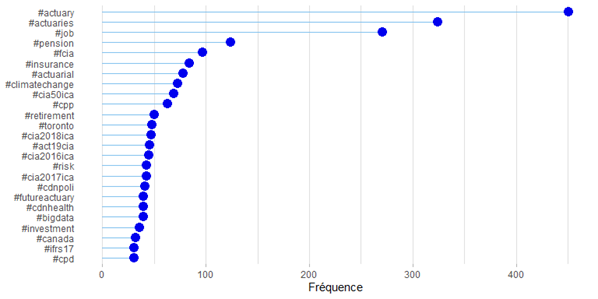
La figure 3 présente les mots-clics que @CIA_Actuaries utilise le plus souvent. Sans surprise, les deux mots-clics les plus courants sont #actuary et #actuaries. Autres tendances intéressantes observées :
- #pension est utilisé plus souvent que #insurance, et trois des mots-clics les plus fréquents semblent se rapporter à l’actuariat relatif aux régimes de retraite (#pension, #cpp et #retirement).
- #toronto est le mot-clic le plus courant concernant les villes.
- #climatechange et #bigdata, qui se rapportent à des domaines en émergence, sont au nombre de 25 mots-clics les plus fréquents.
Figure 3 : Les 25 mots-clics les plus souvent utilisés par @CIA_Actuaries
Nuages de mots-clés
Les figures 4 et 5 présentent les mots (qui ne sont pas des mots-clics) utilisés le plus couramment par @CIA_Actuaries. Les nuages de mots-clés montrent que les mots qui ne sont pas des mots-clics utilisés sont très semblables aux mots-clics utilisés. Par exemple, #actuary et « actuarial ». Il est également évident que @CIA_Actuaries fait référence à d’autres organismes dans ses tweets (p. ex, SOA, ASNA).
Figure 4 : Mots les plus couramment utilisés par @CIA_Actuaries

La figure 5 est divisée selon les mots les plus courants dans les publications partagées (en bleu pâle) et les mots les plus courants dans les publications qui ne sont pas partagées (en bleu foncé). La tendance la plus évidente observée indique que les mots « job », « posting » et « bank » (peut-être pour faire référence aux « banques » d’emploi) ne font souvent l’objet d’aucun partage.
Figure 5 : Mots les plus couramment utilisés par @CIA_Actuaries selon les publications partagées et non partagées

Sentiments
La technique d’analyse de sentiments consiste à attribuer une note à un groupe de mots, par exemple un tweet, et sert à déterminer si celui-ci est plutôt positif ou négatif. Par exemple, la phrase « Les régimes de retraite aident les Canadiens » dégage un sentiment positif. La phrase « Les régimes de retraite n’aident pas les Canadiens » dégage un sentiment négatif.
On recourt au Lexicoder Sentiment Dictionary pour définir le sentiment rattaché aux mots dans tous les tweets de @CIA_Actuaries. On compte ensuite pour chaque mois le nombre de mots positifs et négatifs. Les résultats sont présentés aux figures 6 et 7.
Figure 6 : Note relative au sentiment pour @CIA_Actuaries par mois
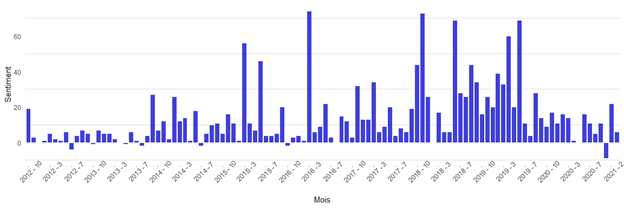
En règle générale, les textes publiés par @CIA_Actuaries sont plutôt positifs. On n’observe que quelques mois où le sentiment est négatif, mais la note est plutôt faible.
Figure 7 : Compte des mots positifs et négatifs pour @CIA_Actuaries par mois
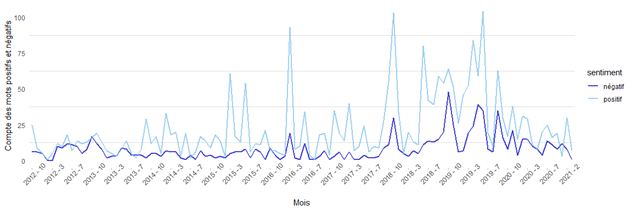
La figure 7 montre les mêmes résultats que la figure 6, mais sous une forme différente. Dans la figure 6, la note relative au sentiment équivaut au compte de mots positifs dont on a soustrait le compte de mots négatifs.
En conclusion
Ce petit ensemble de données nous permet :
- De déterminer le sentiment qui se dégage des tweets de l’Institut (et les tendances à cet égard au fil du temps) à l’égard de certains sujets ou enjeux;
- D’évaluer l’accueil que reçoivent les mots-clics souvent utilisés de la part de l’auditoire;
- De déterminer si certains mots ou mots-clics déclenchent des réactions positives ou virales chez les abonnés.
L’exemple de @CIA_Actuaries est un exercice productif. Bien qu’il ne vise pas à apporter une valeur particulière à la profession actuarielle, il montre ce que les médias sociaux sont en mesure de nous apprendre. Les sociétés d’assurance pourraient également tirer profit d’une telle démarche.
La possibilité de recueillir, de quantifier et d’analyser les données de manière utile contribue à prédire plus efficacement les résultats et d’exercer plus rapidement un jugement plus judicieux et pratique. Alors que les données deviennent un moteur de croissance économique essentiel, les médias sociaux, qui n’ont déjà été qu’une vague idée secondaire pour stimuler les affaires, offrent aujourd’hui une mine de possibilités.
Autres lectures
- package quanteda R : https://tutorials.quanteda.io/
- Package rtweet R : https://github.com/ropensci/rtweet
- R for Data Science : https://r4ds.had.co.nz/
N’oubliez pas de garder le contact avec l’ICA sur les réseaux sociaux!
Cet article reflète l’opinion de l’auteur et il ne représente pas une position officielle de l’ICA.


